
《π0: A Vision-Language-Action Flow Model for General Robot Control》 Paper Reading
基本信息
系列作为以基于流的VLA模型,已经在领域内成为经典工作。作为刚刚入门的研究者,深入且仔细地阅读相关论文是必要的。因此,本文作为面对刚刚入门Embodied AI的初学者,对其中大多数的专有名词进行了深入浅出的解释。
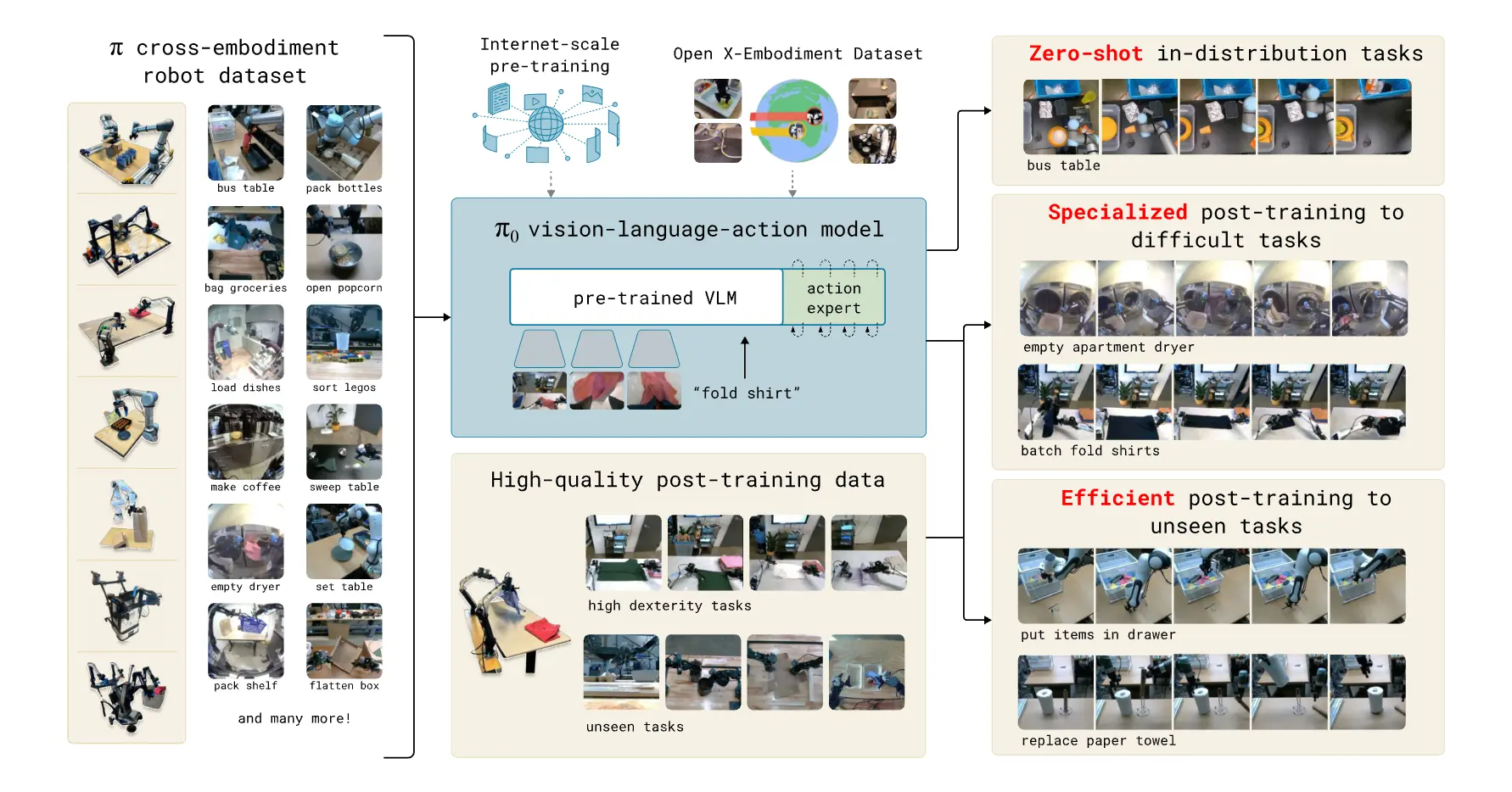
这篇工作由Physical Intelligence团队提出,他们解决的问题是:能否构建一种真正具有base model意味的机器人策略,使得其可以像LLM或VLM那样。首先构建一个通过大范围数据进行pre-train的base model,再通过post-train获得面向具体任务的高质量执行能力。论文提出的 ,正是在这个目标下设计的一种 Vision-Language-Action(VLA) 模型:它以预训练视觉语言模型为骨干,把机器人状态与动作接入同一系统,并通过 flow matching 生成连续动作 chunk,从而面向高频、精细、长时程的真实机器人控制。
研究背景
近年来,机器人学习正在明显地受到大模型范式的影响。传统机器人策略大多依赖单任务、单平台、特定环境的数据与训练流程,泛化能力有限;而大语言模型与视觉语言模型则展示了一个相反的方向:通过大规模、多来源、多任务预训练,模型可以在广泛任务上形成统一表征与迁移能力。 论文的出发点正是:机器人领域是否也能复制这种范式,把大量不同机器人、不同任务、不同环境中的数据统一起来,训练出一个广义的机器人基础策略。作者认为,这种路线有机会同时缓解机器人学习中最核心的三类困难:数据稀缺、泛化不足、鲁棒性不足。
然而,机器人不能简单照搬 LLM 的做法。原因在于机器人控制比文本生成多了一个根本难点:动作不是离散符号,而是连续的、实时的、物理约束下的执行信号。 一个语言模型可以逐 token 生成句子,但机器人如果也用粗粒度离散 token 的方式建模动作,就会在高频控制、精细 manipulation、长时程动作连贯性上遭遇瓶颈。因此,这篇论文提出 ,回答了:如何在保留 VLM 高层语义能力的同时,如何为机器人动作设计一种更适合连续控制的生成机制。
关键概念解释
VLA是什么?
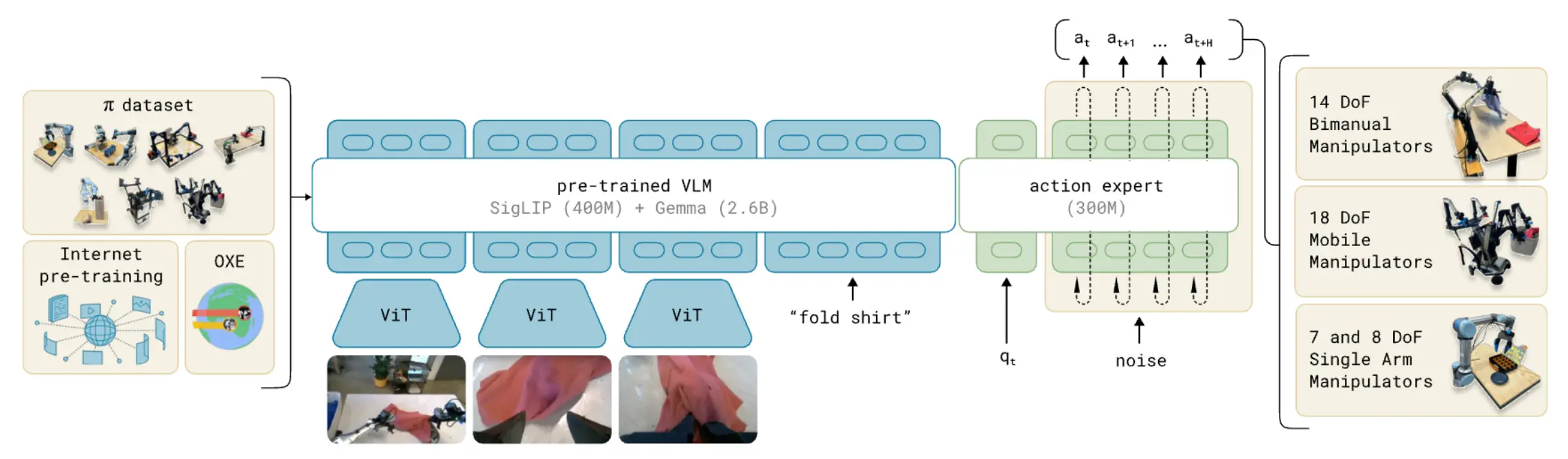
VLA 即 Vision-Language-Action model。它可以视为 VLM 在机器人控制场景下的自然扩展:输入不再只是图像和语言,输出也不再只是文字,而是机器人动作。π0 的基本结构就是把多路图像、语言指令和本体状态联合编码,然后输出未来的一段动作序列。
Cross-embodiment 是什么?
论文中的 cross-embodiment training,指的是把不同机器人本体的数据统一放进同一个模型中训练。这里的 embodiment 可以理解为“身体形式”或“机器人构型”。不同机器人有不同的相机配置、关节维度、底盘形式、双臂或单臂结构。 在 7 种不同机器人配置和 68 类任务上进行统一训练,包括单臂、双臂、移动双臂等平台。作者的目标不是训练 7 个独立策略,而是训练一个能在多个 embodiment 上共享知识与能力的统一模型。
Action chunking 是什么?
论文中的动作并不是“每一步预测一个动作”,而是一次性预测未来一小段动作序列。形式化地说,模型输出的是一个动作 chunk
其中论文中采用 。这意味着模型一次生成未来 50 步动作。这样做的意义有两点:其一,动作会更加连贯,不会每个时刻都重新做全局决策;其二,大模型推理的频率要求下降,更适合高频精细控制。
Flow matching 是什么?
这是整篇论文最关键的技术点之一。它本质上是一种连续生成方法,与 diffusion 有亲缘关系。直观地说,模型不是直接输出最终动作,而是从噪声出发,逐步把噪声“推”向正确动作分布。 在训练阶段,真实动作会被加噪,模型学习一个向量场 告诉系统如何把带噪动作逐步变回目标动作;在推理阶段,则从高斯噪声初始化,通过若干步积分逐渐生成动作 chunk。论文采用了前向欧拉积分,并在实验中使用 10 步积分。
模型结构
总体架构
的主体仍然是一个 transformer 式的多模态骨干。图像由图像编码器提取特征,再映射到与语言相同的 embedding 空间;语言作为标准的离散 token 输入; 机器人的本体状态 也被线性映射到序列中。 与经典的 OpenVLA-like 之类工作不同的是, 并不是简单的将动作空间离散化为 token 后用语言模型的自回归式生成。而是引入一个专门 action expert,用来处理机器人状态和带噪动作,并通过 flow matching 生成连续动作分布。
Action expert
论文的整体采用了类似“大脑小脑协同的双专家结构”,图像和语言 token 由较大的 VLM backbone 处理,而机器人特有的输入输出,即本体状态 与离散动作 chunk ,由单独的action expert 处理。
输入输出形式
模型的输入观察可以写成
其中包括多路 RGB 图像、语言指令以及本体状态;输出是未来动作 chunk
一些问题
在阅读完这些后,一个自然的问题出现了。VLM backbone 是如何把监督信息传递给 action expert 进行动作输出的?
原始的 Transformer
首先,我们从最原始的 transformer 架构开始分析。
Transformer 最核心的操作是: 序列里的每个 token,都去读取其他 token 对自己有用的信息。
假设你有一串 token:
每个 token 都会被映射成三个向量:
读者可以朴素的理解为:
- Query :我现在想找什么信息
- Key :我这里有什么信息标签
- Value :真正携带的信息 然后第 个 token 会拿自己的 query 去和所有的 token 的 key 做相似度计算:
再把所有的 token 的 value 按这个权重加权求和:
于是 就是“第 个 token 从整段上下文里读取到的信息”
回到
有了原始 Transformer 的直觉之后,我们就可以重新看 里最关键的问题:VLM backbone 到底是如何把图像、语言和当前状态中的信息,传递给 action expert 来生成动作的?
要回答这个问题,首先需要纠正一个很常见的误解。初学者在第一次接触这类模型时,会下意识地把它想成“前面一个 VLM 编码器先把图像和文字压缩成一个全局特征向量,后面一个动作模块再拿着这个向量去输出动作”。但 并不是这样工作的。实际的方法是:先把不同模态都变成统一 token 空间中的序列对象,再让这些 token 通过 self-attention 在同一个 Transformer 中进行信息交互。换句话说,信息并不是以“一个摘要向量”的形式从 backbone 单向传给 action expert,而是以前缀上下文的形式,被动作 token 通过 attention 动态读取出来。
从输入形式上看,模型的 observation 为
其中 是多路图像, 是语言命令, 是机器人本体状态。图像会先经过 image encoders,本体状态 也会经过相应编码器与线性投影,最终都被映射到与语言 token 相同的 embedding space 中。也就是说,在真正进入 Transformer 之后,模型面对的已经不再是“图片”“文本”“状态”这几种彼此割裂的输入,而是一段统一的多模态 token 序列。
此时, 中的 VLM backbone 所做的事情,就可以用最原始的 Transformer 语言来描述:图像 token、语言 token 与状态 token 在多层 self-attention 中彼此读取信息,于是每一个 token 都不再只是“自己原来的那点含义”,而是逐渐变成了一个带有上下文条件的表示。例如,某个视觉 token 在最开始可能只对应“画面中的一块布料边缘”,但在经过与语言命令“fold the shirt”以及本体状态 的多轮 attention 交互之后,它会逐渐变成“当前任务下需要被关注的衣物局部,并且与当前机械臂姿态存在控制相关性”的一种条件表示。这种从“原始输入”到“上下文化表示”的变化,本质上就是 VLM backbone 在做的事情。
接下来,action expert 才真正进入问题中心。论文把 描述为一个single transformer with two sets of weights,也就是说,它在整体上仍然是一个统一的 Transformer,但内部存在两套不同的专家权重。图像与语言 prompt 被路由到较大的 VLM backbone,这部分来自 PaliGemma 的预训练权重;而那些在原始 VLM 预训练中没有出现过的机器人特有输入,也就是 ,则被路由到单独的 action expert。更关键的是:这两个 expert 之间并不是彼此完全独立的,它们只通过 Transformer 的 self-attention 层进行交互。
因此,从机制上讲,VLM backbone 向 action expert 传递信息的方式可以被理解为:前缀中的图像、语言和状态 token 先被编码成一段可被访问的上下文记忆,而后缀中的动作 token 再拿着自己的 query 去读取这段前缀记忆中的 key 和 value。这也是为什么在推理时,论文专门提到可以缓存 prefix 对应的 attention keys and values,而在每一次 flow matching integration step 中,只需要重算 action token 所对应的后缀部分。换句话说,真正被“传递”给 action expert 的,并不是某个单独 pooled feature,而是整个 observation prefix 的 contextualized KV memory。
理解这一点之后,我们还需要继续追问:action expert 在读取了这些跨模态条件信息之后,究竟输出的是什么?这里就进入了 与 OpenVLA-like 模型最本质的区别。论文并没有让 action expert 像语言模型那样“自回归地预测下一个离散动作 token”,而是让它去建模一个未来动作 chunk 的连续条件分布。具体而言,论文定义
其中 ,表示未来的一整段动作序列。训练时,真实动作 chunk 不会被直接送入模型,而是先加上噪声,构造出
然后,模型的任务不是“直接回归 ”或者“输出下一个动作 token”,而是输出一个向量场
它表示:在当前 observation 条件下,这个 noisy action chunk 应该往哪个方向被修正。
当前的 只是一个带噪的动作草稿,它并不是真正要执行的动作;action expert 在看完图像、语言和当前状态之后,会告诉你:“在这个场景下,这段动作草稿应该往哪个方向调整,才能逐渐逼近合理的未来轨迹。” 于是,训练过程学到的其实不是一个静态动作,而是一个去噪向量场;推理过程也不是一步生成动作,而是从纯噪声 出发,用 Euler integration 反复迭代:
论文中使用了 10 步积分,最终才得到真正执行的动作 chunk。
这时还有一个非常值得注意的细节:单个 action chunk 内部的动作并不是 causal 的,而是彼此双向可见的。论文中说明, 使用的是一种 blockwise causal attention mask:、、 这三个块之间不能看未来块,但块内是 full bidirectional attention,而最后的 noisy action block 可以看到完整输入前缀。这个设计意味着,模型不是把动作 chunk 中的 50 个未来动作当成 50 个彼此隔离、逐个预测的小 token,而是把它们当作一个整体的连续轨迹片段来联合修正。对于机器人控制来说,这一点非常自然,因为未来动作往往不是“第 步决定完了再想第 步”,而是应该作为一小段协调的轨迹被整体建模。