
Paper 1
MM-ACT: Learn from Multimodal Parallel Generation to Act
Introduction
当前 VLA(Vision-Language-Action)模型的核心问题可以抽象为两个维度的矛盾:一方面,基于大规模预训练的 VLM 在语义理解与视觉感知上具有明显优势,但其建模目标本质上是静态 token prediction,缺乏对物理世界动态过程的显式建模;另一方面,动作生成通常依赖 imitation learning 或 diffusion-based policy,这类方法强调时序与动力学建模,但往往与 VLM 的预训练目标不一致,从而在联合优化时产生目标错配的问题 。
现有方法通常沿三条路径发展:一类方法将 VLM 与 action expert 解耦,通过 latent representation 进行信息传递(如 π0),本质上仍然是“语义 → 控制”的级联结构;第二类方法通过引入视觉预测或 world model,使模型能够对未来状态进行建模,从而间接提升规划能力,但这类方法往往更偏 prediction 而非 task-oriented decision;第三类 unified VLA 方法尝试在同一模型中统一 text、image 与 action 的生成,但大多继承 autoregressive 或 hybrid decoding 机制,导致推理效率低或训练复杂度较高 。
MM-ACT 的出发点在于重新定义这一问题:不是在已有架构上增加模块,而是直接在生成范式上做统一。具体而言,它将三种模态全部离散化为 token,并在同一 Transformer 中,通过 mask token prediction 的方式进行建模,从而在训练目标层面统一 text、image 与 action 的生成过程。
模型整体设计
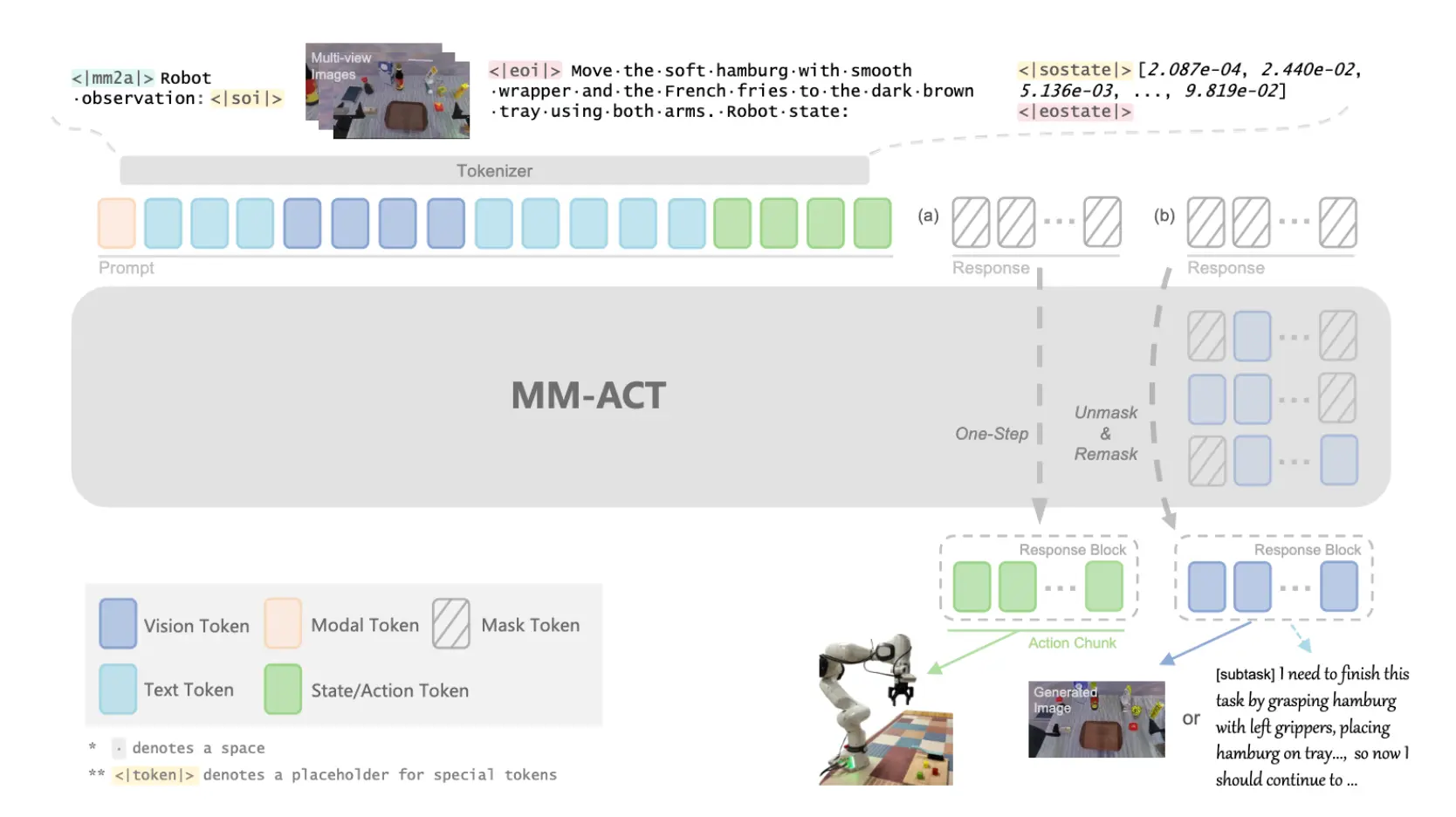
MM-ACT 在结构上仍然采用 Transformer,但关键变化在于 attention 机制与序列构造方式。模型使用 双向 attention(bidirectional attention),允许任意 token 之间进行信息交互,而不是像 autoregressive 模型那样采用因果掩码。
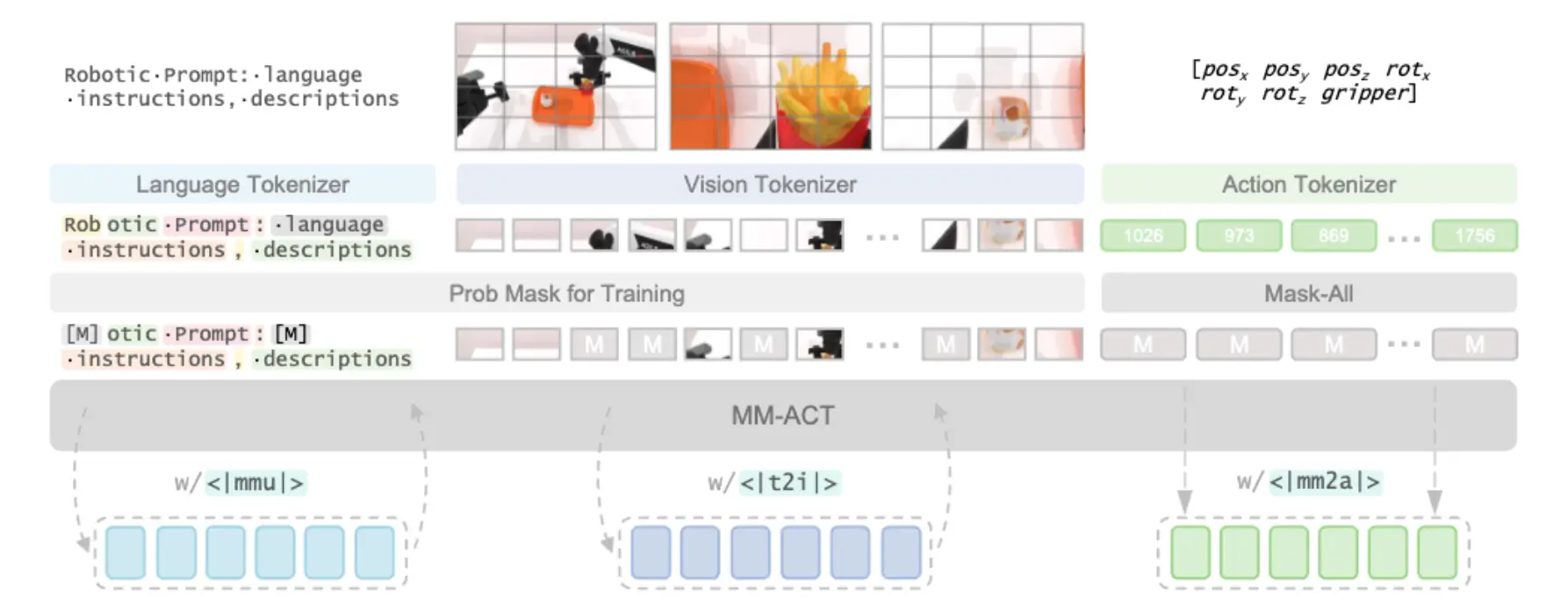
在输入层面,模型将文本、图像以及机器人状态统一编码为离散 token,并拼接为一个共享序列。不同模态采用不同 tokenizer:文本使用 LLaDA tokenizer,图像使用 Show-o 的量化器(8192 token codebook),机器人状态与动作使用 bin tokenizer(2048 token) 。这种设计的关键在于,所有模态在进入 Transformer 后处于同一 token 空间,从而使 cross-modal attention 成为自然的交互机制。
模型在输入序列前引入一个 modal token,用于指定当前的生成任务;同时在序列后附加一个固定长度的 <mask> block,作为目标生成区域。在推理时,模型根据 modal token 决定生成 text、image 或 action,对应不同的任务类型(task planning、future prediction、action generation)。
上下文共享的多模态学习
MM-ACT 的一个核心设计是 Context-Shared Multimodal Learning,其关键在于:三种模态的生成任务共享完全相同的输入上下文,仅通过 modal token 区分任务类型。
形式上可以表示为:
其中 sharedinput 包含多视角图像、语言指令、文本描述以及机器人状态等信息。对于不同任务,仅在 context 后附加不同类型的 mask block,例如 text block(用于任务规划)、image block(用于未来状态预测)以及 action block(用于动作生成)。
这一设计的本质含义是:模型不是分别学习三个独立任务,而是在同一条件分布下学习三个 conditional generation problem。这种共享上下文的机制使得不同模态之间可以通过 attention 自动建立关联,从而实现跨模态知识迁移。
多模态统一目标
在训练目标上,MM-ACT 将三种模态统一为 mask token prediction 问题。具体而言,对于每一种模态的 token 序列 ,通过随机 mask 操作生成 ,其中每个位置以概率 被替换为 <mask> token。这个过程可以理解为离散 diffusion 中的 forward process:
不同模态采用不同的 mask schedule:文本使用线性 schedule,而图像与动作使用 cosine schedule,以对齐连续 diffusion 的噪声分布 。
模型的目标是在给定 与 的条件下,同时预测所有被 mask 的 token:
其中仅对 mask token 计算交叉熵损失。
一个关键特例是 action 模态:在训练时固定 (t=1),即所有 action token 都被 mask,这意味着模型需要在单次 forward 中恢复完整的 action 序列。这一设计直接决定了后续的并行解码策略。
两阶段训练策略
模型采用两阶段训练流程。第一阶段仅训练 text 与 image 模态,将 action loss 权重设为 0,使模型先学习语义理解与视觉预测能力;当这两种模态收敛后,进入第二阶段,重点训练 action 生成,同时将 text 与 image 的权重降低至较小值(约 0.05–0.1)以维持其能力 。
这一策略的作用可以理解为先构建一个“语义 + 动态”的表示空间,再在该空间上学习控制策略,从而避免 action 学习过程过早干扰 representation learning。
并行解码策略
在推理阶段,MM-ACT 采用 block-level parallel decoding,而不是传统的 token-by-token autoregressive 生成。具体策略在不同模态之间存在差异。
对于 text 与 image,模型采用 re-mask 迭代解码策略。初始时输入部分 mask token,模型进行前向传播得到 logits,然后根据置信度选择一部分 token 进行更新,同时对低置信 token 重新 mask,并重复这一过程若干步。这一过程本质上等价于离散 diffusion 的逐步去噪。
对于 action,模型采用 one-step parallel decoding,即在输入全 mask 的情况下,通过一次 forward 直接生成完整的 action token 序列。这种设计显著降低了推理延迟,使模型能够满足实时控制的需求。
实验表明,当 action chunk 较小时(如 8),re-mask 策略并不会带来性能提升,反而增加计算开销;而在 chunk 较大时虽然性能有所提高,但推理时间显著增加。因此最终选择 one-step decoding,以实现约 40Hz 的控制频率 。
实验结果与分析
在 LIBERO 基准测试中,MM-ACT 达到 96.3% 的成功率,超过现有方法;在 RoboTwin2.0 中达到 52.38%,并在真实 Franka 机器人任务中取得 72.0% 的成功率 。
进一步分析表明,多模态联合训练对 action 生成具有显著促进作用。仅使用 action 训练作为 baseline,引入 text 可提升约 3.37%,引入 image 可提升约 5.62%,同时引入两者则提升约 9.25%。这一结果表明,视觉预测信号对控制的帮助大于语言规划,但两者结合能够提供互补信息。
在模态质量方面,图像生成在联合训练后持续提升,而文本生成在第二阶段出现性能下降。这一现象与训练过程有关:文本任务较容易收敛并发生过拟合,而图像任务收敛较慢,能够持续从联合训练中获益 。
总结
MM-ACT 的核心贡献并不在于引入新的模块,而在于将 VLA 问题重新表述为一个统一的多模态离散生成问题。通过将 text、image 与 action 映射到同一 token 空间,并采用一致的 mask prediction 目标,模型避免了 autoregressive 与 diffusion 之间的目标不一致问题。在此基础上,通过共享上下文的多模态训练方式,使不同模态之间形成协同,从而显著提升 action 生成能力。在推理层面,通过区分 one-step 与 re-mask 两种解码策略,实现了效率与生成质量之间的结构性权衡。